Why Evertune’s 100x Prompting Method Leaves Profound in the Dust
In the fast-moving world of AI visibility analytics, scale matters. Platforms like ChatGPT, Claude, Gemini, and Perplexity never give identical answers . their outputs vary with every generation.
So, if you’re testing how often your brand shows up in AI responses, how many times you run each prompt makes all the difference.
That’s where Evertune has built a clear edge.
Evertune’s 100x Prompting vs. Profound’s Smaller Samples
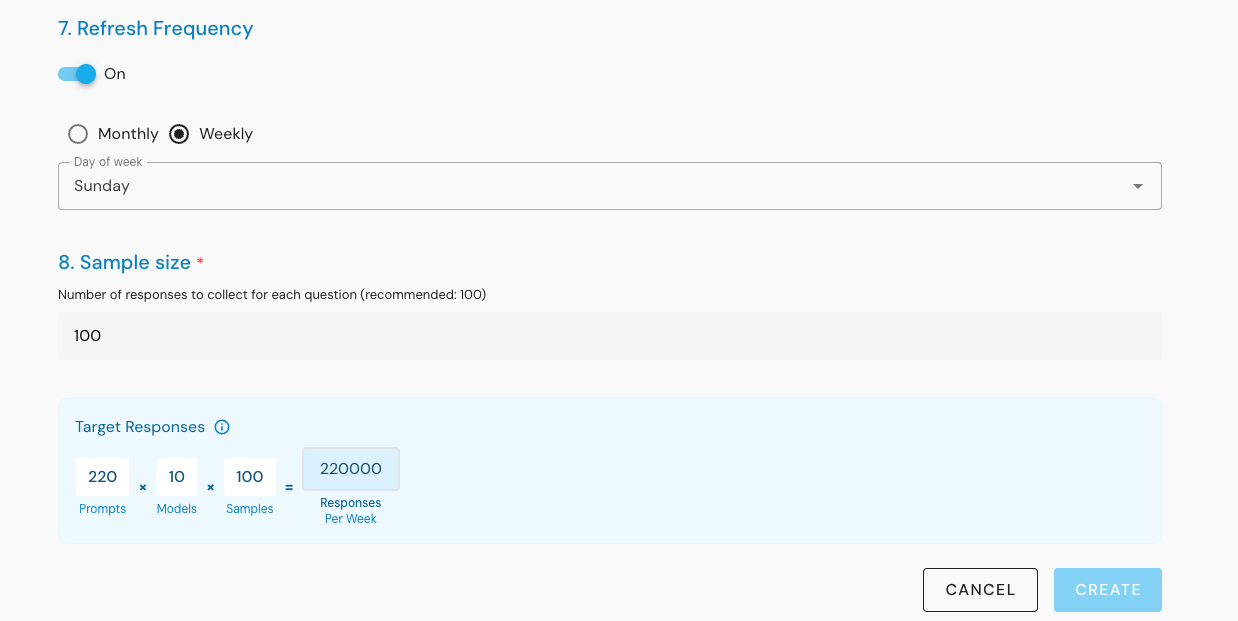
While competitors such as Profound tend to run each prompt only 6–7 times per model, Evertune goes much further . running every prompt 100 times for every supported API and model.
That’s not just a bigger number . it’s the difference between anecdote and evidence.
With 100 samples per model, Evertune doesn’t just capture what AI says once; it measures how consistently AI says it.
Example: “Your brand appears in 82% of AI responses for unaided smartwatch queries.”
By contrast, Profound’s smaller sample sets aren’t statistically significant and can fluctuate by 30–40% between runs due to random model variation. That means a “gain” or “drop” might not reflect any real change in brand visibility at all.
Why Bigger Samples Mean Better Accuracy
Large language models are probabilistic systems . their answers depend on internal randomness, sampling temperature, and contextual drift.
Running a prompt 6 or 7 times provides a rough sketch; running it 100 times provides a statistical portrait.
More samples mean:
- Reduced variance and fewer false trends
- Repeatable averages that hold up over time
- The ability to separate signal from noise
In short, Evertune’s data is statistically valid and confidence-weighted . Profound’s limited testing simply can’t reach that level of reliability.
Multi-Model, Multi-Market Precision
Evertune’s prompting doesn’t happen in a vacuum. Each of those 100 iterations is repeated across multiple AI APIs (OpenAI, Anthropic, Google, and others) and localized markets.
That allows analysts to see:
- Which models favor or underrepresent certain brands
- How visibility shifts between countries and languages
- How retraining cycles affect brand rankings
Smaller-sample systems like Profound can provide broad directional data, but they lack the resolution to uncover these subtler . and often more valuable . insights.
The Statistical Edge
Bigger datasets create smaller error margins. Here’s how that translates:
| Platform | Prompts per Model | Model Coverage | Market Simulation | Data Confidence |
|---|---|---|---|---|
| Profound | 6–7 | Moderate | Single or Limited | Low . ±30–40% swings |
| Evertune | 100 | Multi-API | Multi-Country | High . Statistically Reliable |
Evertune’s larger samples make its outputs far more stable and actionable, while Profound’s narrower tests remain prone to those 30–40% fluctuations from random model variation.
A Fair Note on Profound
To be fair, Profound can still be a useful entry-level tool for small businesses or local shops just beginning to explore AI search visibility.
Its lighter setup and quick turnaround make it accessible for teams that only need general direction . not deep statistical accuracy.
But as soon as you’re operating across multiple markets or tracking competitive categories, limited data becomes a liability.
At that stage, you need scale and significance . and that’s where Evertune’s methodology shines.
Final Thoughts
Evertune’s 100x prompting framework isn’t overkill . it’s what reliable measurement requires in a probabilistic AI world.
Where Profound’s small-sample results can swing wildly by 30–40%, Evertune’s large-scale testing delivers clarity, repeatability, and actionable truth.
If you want to understand how AI systems really see your brand, you don’t need more dashboards . you need better data.
Evertune provides that foundation.
Profound gives you a snapshot.
Evertune gives you the signal.
Read more about Evertune
Evertune and the Anti-Hallucination Revolution
Today my five-year-old son looked up from his tablet and said,
2025-10-23Perplexity Comet: The AI Browser Changing How We Search and Work
When Perplexity AI launched Comet, it introduced more than another AI-enhanced search tool. It built a completely new kind of browser experience where search, reading, and task execution happen in the...
2025-10-2010 AI Tools That Actually Help You Work and Live Better
Artificial intelligence used to feel abstract, something only researchers or engineers talked about.
2025-10-19